- Hadoop Tutorial
- Hadoop - Home
- Hadoop - Big Data Overview
- Hadoop - Big Data Solutions
- Hadoop - Introduction
- Hadoop - Environment Setup
- Hadoop - HDFS Overview
- Hadoop - HDFS Operations
- Hadoop - Command Reference
- Hadoop - MapReduce
- Hadoop - Streaming
- Hadoop - Multi-Node Cluster
- Hadoop Useful Resources
- Hadoop - Questions and Answers
- Hadoop - Quick Guide
- Hadoop - Useful Resources
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
Hadoop - Big Data Solutions
Traditional Approach
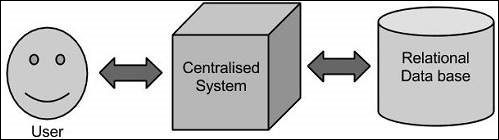
In this approach, an enterprise will have a computer to store and process big data. For storage purpose, the programmers will take the help of their choice of database vendors such as Oracle, IBM, etc. In this approach, the user interacts with the application, which in turn handles the part of data storage and analysis.
Limitation
This approach works fine with those applications that process less voluminous data that can be accommodated by standard database servers, or up to the limit of the processor that is processing the data. But when it comes to dealing with huge amounts of scalable data, it is a hectic task to process such data through a single database bottleneck.
Google’s Solution
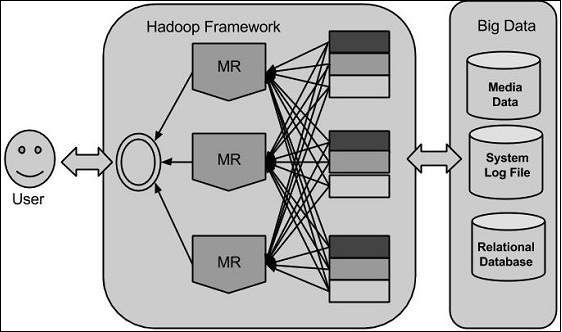
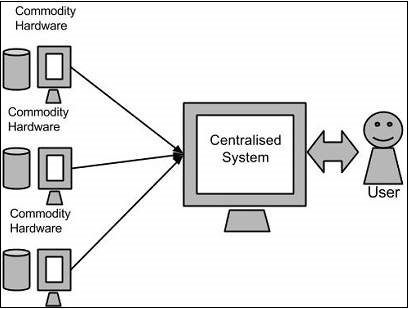
Google solved this problem using an algorithm called MapReduce. This algorithm divides the task into small parts and assigns them to many computers, and collects the results from them which when integrated, form the result dataset.
Hadoop
Using the solution provided by Google, Doug Cutting and his team developed an Open Source Project called HADOOP.
Hadoop runs applications using the MapReduce algorithm, where the data is processed in parallel with others. In short, Hadoop is used to develop applications that could perform complete statistical analysis on huge amounts of data.