- MongoDB Tutorial
- MongoDB - Home
- MongoDB - Overview
- MongoDB - Advantages
- MongoDB - Environment
- MongoDB - Data Modeling
- MongoDB - Create Database
- MongoDB - Drop Database
- MongoDB - Create Collection
- MongoDB - Drop Collection
- MongoDB - Data Types
- MongoDB - Insert Document
- MongoDB - Query Document
- MongoDB - Update Document
- MongoDB - Delete Document
- MongoDB - Projection
- MongoDB - Limiting Records
- MongoDB - Sorting Records
- MongoDB - Indexing
- MongoDB - Aggregation
- MongoDB - Replication
- MongoDB - Sharding
- MongoDB - Create Backup
- MongoDB - Deployment
- MongoDB - Java
- MongoDB - PHP
- Advanced MongoDB
- MongoDB - Relationships
- MongoDB - Database References
- MongoDB - Covered Queries
- MongoDB - Analyzing Queries
- MongoDB - Atomic Operations
- MongoDB - Advanced Indexing
- MongoDB - Indexing Limitations
- MongoDB - ObjectId
- MongoDB - Map Reduce
- MongoDB - Text Search
- MongoDB - Regular Expression
- Working with Rockmongo
- MongoDB - GridFS
- MongoDB - Capped Collections
- Auto-Increment Sequence
- MongoDB Useful Resources
- MongoDB - Questions and Answers
- MongoDB - Quick Guide
- MongoDB - Useful Resources
- MongoDB - Discussion
- Selected Reading
- UPSC IAS Exams Notes
- Developer's Best Practices
- Questions and Answers
- Effective Resume Writing
- HR Interview Questions
- Computer Glossary
- Who is Who
MongoDB - Sharding
Sharding is the process of storing data records across multiple machines and it is MongoDB's approach to meeting the demands of data growth. As the size of the data increases, a single machine may not be sufficient to store the data nor provide an acceptable read and write throughput. Sharding solves the problem with horizontal scaling. With sharding, you add more machines to support data growth and the demands of read and write operations.
Why Sharding?
In replication, all writes go to master node
Latency sensitive queries still go to master
Single replica set has limitation of 12 nodes
Memory can't be large enough when active dataset is big
Local disk is not big enough
Vertical scaling is too expensive
Sharding in MongoDB
The following diagram shows the Sharding in MongoDB using sharded cluster.
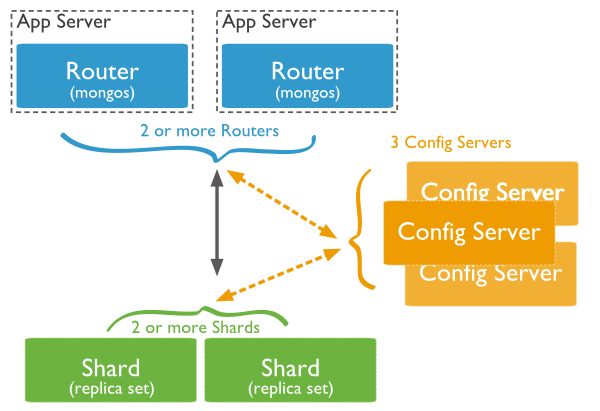
In the following diagram, there are three main components −
Shards − Shards are used to store data. They provide high availability and data consistency. In production environment, each shard is a separate replica set.
Config Servers − Config servers store the cluster's metadata. This data contains a mapping of the cluster's data set to the shards. The query router uses this metadata to target operations to specific shards. In production environment, sharded clusters have exactly 3 config servers.
Query Routers − Query routers are basically mongo instances, interface with client applications and direct operations to the appropriate shard. The query router processes and targets the operations to shards and then returns results to the clients. A sharded cluster can contain more than one query router to divide the client request load. A client sends requests to one query router. Generally, a sharded cluster have many query routers.